

If you would be a real seeker after truth, it is necessary that at least once in your life you doubt, as far as possible, all things. – Rene Descartes.
Conducting research to demonstrate the effectiveness of HR practices is important and valuable. Traditionally, researchers generated such evidence by collecting data using surveys, interviews, or observations. With this data, they gained insight into the workforce and developed practical interventions to improve outcomes (Van den Heuvel & Bondarouk, 2017).
Technological advancements have led up to the digitalization of many Human Resource Management (HRM) processes. As a result, technological advancements generate vast quantities of data that the organization controls. Examples include job applications, absenteeism, performance data, and so forth.
These data have created opportunities and challenges for HR professionals and academics. As a result, HRM is shifting towards a ‘decision science’. Demonstrating the quality of decisions about human capital is key. And if done well this can increase the strategic value of human capital (Van den Heuvel & Bondarouk, 2017).
But in the realm of digitized HRM, how do we ensure that the evidence we base our decisions on is of high quality? How can we make sure that we measure what we intend to measure? That we are able to rule out alternative explanations for our findings? That we draw the right conclusions? And that we are able to generalize such knowledge to other contexts or cases? These questions relate to ‘validity’ – a.k.a. how sound your research is.
In this article, we’ll explain how validity is fundamental to the quality of decision making. We will first introduce the often used Cross-Industry Standard Process for Data Mining (CRISP-DM; Shearer, 2000). The CRISP-DM model explains the (ideal) process of conducting data-driven research. Second, we will explain what validity is and how it impacts the quality of evidence-based HRM decisions. We will explain three different types of validity – internal, external, and construct validity. We will illustrate each with an example related to HR analytics. We will then conclude with suggestions for each type of validity for how to generate evidence.

The CRISP-DM model
The CRISP-DM model reflects the most important steps in implementing data-driven decision making. Of the available models, we chose the CRISP-DM model for its clarity and simplicity.
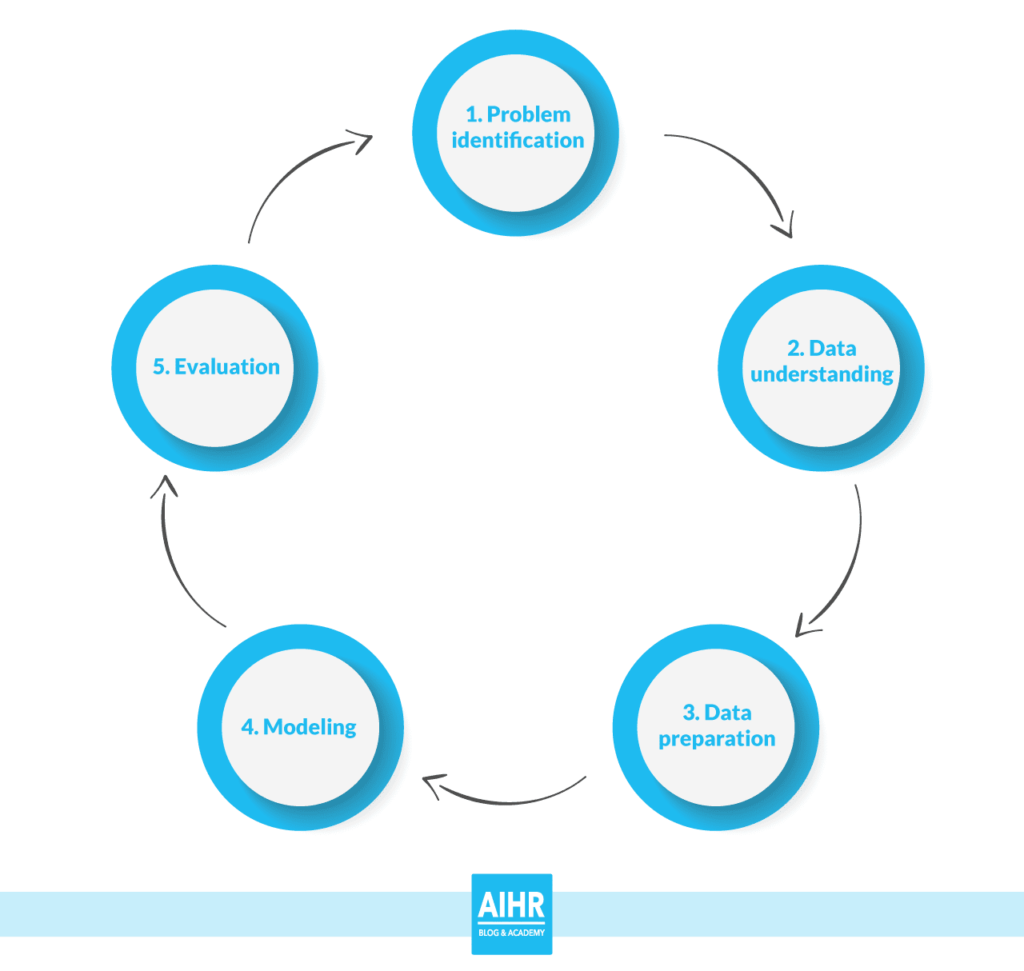
The CRISP-DM model has five different phases. Problem identification, data understanding, data preparation, modelling, and evaluation. We will focus mostly on the so-called design part.
Improving organizational processes and outcomes starts with two phases. First, there is the business, academic, societal, and/or environmental problem (phase 1). Identifying the problem is the first step in improving processes and outcomes. If the problem is not correctly identified, efforts to improve may be in vain. Phase 1 also includes formulating a (research) question related to the problem. It is important to formulate a clear and precise question. If your question is not clear and specific, it’s difficult to really answer the question, and thus solve the problem by conducting your study.
For example, a question may be too broad (e.g. “who are the most creative employees at the workplace?”). Or it may contain hidden assumptions and multiple questions in one (e.g., “why is authentic leadership more effective than ethical leadership?”). Or it contains a what-if statement (e.g., “would the organization be more profitable if it had a different leader in the 1990s?”). These questions are difficult if not impossible to answer.
Instead, a good research question is clear, precise, specific, and requires an iterative process. And, – most importantly – it can be answered by conducting your study. If we look at the examples above, better versions of research questions are: “are employees that score high on openness to experience more creative compared to people that score low on openness to experience?” or “does empowering leadership promote employee creativity at the workplace?”.
Second, there is a clear understanding of the data (phase 2). After identifying the problem, it is important to think about the data you have available. For example, does the data represent the variables that are included in your research question? What is the quality of the data? Does the data represent the broader population you want to study? Is the data at the right level of analysis (i.e., employee level or aggregated group or unit level data)? Critically evaluating the data is an important step. The quality of your data will have an enormous impact on the results. And also on the decisions you make based on that. We will discuss this in more detail later when we explain validity.
Validity
Validity refers to how sound your research is. It involves both the design of the research and the methods that are used. So when can we say that a particular research is valid? In valid research, the findings and conclusions truly represent the phenomenon you are claiming to measure. Valid claims are solid claims that are difficult (if not impossible) to dispute.
Whether your research is sound has an enormous impact on the quality of the conclusions and on the effects of implemented practices based on those outcomes. Yet it is important to highlight at this point, that there is no such thing as ‘perfect validity’.
Scientists are trained to implement the Cartesian notion of doubt that we referred to at the beginning of this article, to the extreme. Every aspect of a study is scrutinized before accepting a conclusion as a (tentative) “truth”. Labelling research as valid or invalid is therefore not the focus. Think of demonstrating validity as an exercise in optimization (that never ends). The CRISP-DM model also reflects this. Evaluation of the process, outcomes, and decisions (phase 5), leads back to phase 1.
So validity helps us to think about important questions. Did we measure what we intended to measure? Can we rule out alternative explanations? Are we confident about the conclusions we draw? Can we generalize the results to other contexts or cases or are the results situation-specific? These questions need an answer before making data-driven decisions.
There are different types of validity. The following three types are particularly relevant for people analytics:
- Internal validity: Does the data support claims about cause and effect relationships? For example, we train a classifier to ‘predict’ turnover, based on changes to employees’ social media profiles. Does this mean that identified characteristics are a cause of turnover? As we will see below, a relationship is necessary for establishing causality. But it is not sufficient for establishing causality.
- External validity: Can you apply conclusions outside the context of that study? For example, the Amsterdam-based workforce is more engaged after implementing a leadership intervention. Can you expect the same positive results in Tokyo or New York?
- Construct validity: Do you measure what you intend to measure? For example, you measure employee engagement. Does the data really capture engagement and nothing else? This question has important consequences for the explainability of any decisions.
This again illustrates the importance of phase 2 to the evaluation of validity. Data-understanding is fundamental to the quality of decision making.
Below we explain the three types of validity. We will provide examples, and suggestions to improve them in data-driven decision making.
Internal validity
Is the association consequential and can you rule out alternative explanations?
Mike works for a large multinational organization. The organization aims to increase the productivity of their workforce. They will examine the data from their back-office system. The goal is to determine which actions influence the productivity of their employees. After analyzing the data, they conclude that if they pay Mike a higher salary, he will be more productive.
Here, the data suggests that there is a relationship between salary and productivity. But concluding that salaries should go up to boost productivity is premature.
Of course, employee productivity could increase when salaries increase. But it’s actually somewhat more complicated than that. Productive people may get paid more because they were already hard workers. They may work hard because they like what they do, regardless of the pay, or their productivity may increase because of experience rather than pay.
Alternatively, the found relationship between pay and performance was just a matter of chance. It may not be replicated the next time. Thus relying only on correlational analysis may paint the wrong picture. If you don’t trace the steps in the analysis this may hurt rather than improve productivity.
So how do we find out what the actual cause of high productivity is? Internal validity is the extent to which you can say that no other variables except the one you are studying caused the result. So, we want to be able to say that no other cause than pay causes higher productivity. Not personality, motivation, experience, or pure chance. We would like to say that pay and pay alone makes employees such as Mike become more productive.
To establish that pay causes performance, we must fulfill three criteria.
First, we must establish an association between pay and performance. A relationship cannot be a causal relationship if there is no relationship to start off with.
Next, we should rule out alternative explanations. This involves showing that the relationship still exists when we isolate it from other possible causes. If we look back at our example, what if superior machinery was responsible for productivity? In this case, machinery is the ‘true’ cause of productivity, and not pay. So we could test if the relationship holds when we only examine departments that have superior machinery. Then we could rule out superior machinery as an alternative explanation.
Finally, we must show that cause precedes effect. This is often the most difficult condition to fulfill. For pay to cause productivity, it should happen before productivity. An increase in salary at time 2 cannot explain that employee’s productivity at time 1. So we need to introduce a planned change to the cause (salary). And then, we need to examine whether the presumed effect (productivity) changes as a result. Then we can establish ‘temporal precedence’ of cause over effect.
One possibility is to make use of a so-called “pre-test/post-test” design. In this design, you measure productivity before you raise an employees’ salary. Then you do this once more after they have had a raise in salary, all other things being equal. This makes it possible to examine changes in productivity as a result of the salary raise.
Other variables such as motivation and equipment should be stable between the measurements. This way you can isolate the influence of salary on productivity. Of course, it is not easy to rule out all alternative explanations. But the harder we try, the more valid and valuable our decision making becomes.
Another option would be to add a ‘control group’ to your pre-test/post-test design. Besides testing a specific group before and after the raise in salary, you conduct a pre- and post-test to a second group. This group, however, will not get a raise in salary between the different tests. So, for the control group, nothing changes. Using a control group will allow you to also rule out things such as regression to the mean. Another benefit is that you can rule out external effects. For example, after the pre-test there were many sunny days, which improved the employees’ mood and, as a result, their productivity.
External validity
Are the results generalizable?
The company would like to test whether a specific leadership style will make employees more engaged. They find a positive relationship between transformational leadership and employee engagement. Like the situation above, there could be several explanations for high engagement. Imagine that alternative explanations were eliminated. They are also able to say that engagement was a direct result of a transformational leadership intervention. So we could claim that the study is internally valid.
Mike and his colleagues work at the Amsterdam headquarters. Does this necessarily mean that the result is also true for the workforce at the New York headquarters? Or the Tokyo headquarters? In other words, can we generalize the results to different contexts? The extent to which results are generalizable is what researchers call external validity.
Let’s say we want to increase employee engagement at different locations (or different teams or units). Then we should try to rule out environmental boundary conditions. Examples are cultural aspects, or the composition and background of the workforce. Thus, if we want to increase engagement in NY and Tokyo, good external validity is key. We need to know if a transformational leader is also appreciated there.
But how can we establish external validity?
A critical concept in the evaluation of external validity is the population. With population we mean the group of entities (employees or departments) for which we want our decisions to be valid. We want to make an externally valid claim about all employees in Mike’s organization. So, we want to make sure that the data are representative of the entire population. This comes down to ensuring that we do not exclude or underrepresent a subgroup in the data.
Imagine that because of GDPR compliance policies you need consent for analyzing the data of the European employees. And this is not needed for the Japanese and US-based employees. Thus possibly the European employees will be underrepresented. This would cast doubt on the external validity of the study.
The best way to ensure high external validity is random selection. In this case, each ‘type’ of employee (with regard to education, nationality, etc.) has an equal chance to be represented in the dataset. But such random selection is hardly ever feasible. Random selection would require extensive information about each individual. But what happens when you don’t use random selection? Then you are not sure whether the result will hold for the population.
So you need to make sure that certain subgroups are not under or overrepresented. That way, you can generalize the results to the whole population (e.g., all employees). But sometimes, using an agile perspective, you are not interested in the entire population. Instead your interest is a specific group (e.g., ‘talents’, ‘star employees’, ‘potentials’). If this is the case, it is important that your sample does represent the ‘talent population’. This way, the results can still be valid for this group. The truth might be entirely different for another population, so be mindful of this.
Sometimes one type of validity may come at the cost of the other. Looking at the above example, imagine that they had collected data from all three headquarters to start off with. In that case, the external validity would clearly be higher. But the internal validity may be lower due to the country differences in the data. So for internal validity, you should keep as many factors constant as possible in the data. But for external validity you need variation to make the results generalizable. It is important to think about these tradeoffs and to find an optimal balance. The research question should be leading in making decisions about which data to collect or use.
Construct validity
Do we measure what we intend to measure?
Let’s go back to the example. To examine employees’ work engagement, the company uses an annual employee survey. In this survey, they measure several different employee attitudes and behaviors, including engagement.
The extent to which you measure what you intend to measure is construct validity. For construct validity, an important question is whether the survey actually measures “engagement”. What if the employee survey does not accurately measure employee engagement? Then it is unclear what an engagement score means and the conclusions we draw from the data, are also not accurate.
In some employee surveys, the scores on all questions – to measure satisfaction, engagement, etc. – correlate highly. It is then unclear what employees had in mind when answering those questions. Does the score represent satisfaction? Climate? Engagement? This means that it is also impossible to draw conclusions from this. It will be unclear what you need to do to enhance engagement.
Contamination and deficiency have an important bearing on construct validity. Contamination occurs when scores on the construct are contaminated with construct irrelevant variance. In our example, gender-related pay inequity could contaminate our measure of pay. Deficiency occurs when only certain aspects of the construct are considered. You may measure Mike’s productivity by capturing only one of several productivity subdomains. For example, ‘time spent’ and ‘revenue generated’. If they are accessible in the data but ‘customer service orientation’ is not, the measure of Mike’s productivity is deficient.
Using scientifically validated measures is an easy way to achieve good construct validity. Such measures have all gone through an extensive construct validation process. In this process, researchers drop questions that are less or unrelated to the construct. Often you can find those measures online, either free of charge or you can buy a license to use the measures. Another development is that organizations and scholars work together in HR analytics projects within organizations.
Conclusion
Technological advances have created opportunities for HR analytics professionals and academics. Organizations have a wealth of data that can help in evidence-based decision making. On top of that, the availability of data helps to increase HR’s strategic value to the business.
But these same technological advances have also created challenges. HR professionals are often not trained to analyze data, let alone assess the validity of that data. Still, making high-quality decisions based on the data is often HR’s responsibility.
We hope that this article provided some insights into conducting sound data-driven research. We also hope that it is now clear why and how validity is fundamental to the quality of decision making.
We introduced the CRISP-DM model. We showed that understanding the problem and the available data are important first steps to ensure the quality of decisions. If the first two phases are well thought through, you are already a long way in the right direction. Still, the fifth phase is perhaps the most important. Evaluating the process and outcomes will help to improve the soundness of your research. As a result, your decision making will be improved.
The key message to keep in mind when it comes to conducting valid data-driven research is as follows. Achieving valid research is not a one-time process, but rather an iterative process. It’s not about conducting the ‘perfect’ research. It is about consciously working on improving the process and data you base your decisions on. Then, and only then, can HR professionals work towards optimizing the quality of their decision making.













