

“To understand God’s thoughts one must study statistics for they are measure of his purpose in the Universe” – Florence Nightingale
As a statistics instructor in the early part of my career, I know how boring statistics can be (to most of us). However, grasping the fundamentals of statistics is critical for your success as an HR professional. Without it, you cannot capitalize on the huge potential data science offers HR.
In this article, I will decipher HR statistics through storytelling. I will answer 19 questions typically asked by young business and HR managers who are about to start their analytics journey.
Question 1: How would you define HR analytics?
Analytics is a combination of the two terms “analysis” & “statistics”. It refers to any analysis driven through the application of statistics. HR analytics is analytics applied to the domain of HR. These analytics can be advanced predictive analytics, or basic, descriptive statistics. This means that HR analytics is a data-driven approach to managing people at work (Gal, Jensen & Stein, 2017).
Question 2: So how does the discipline of statistics help HR?
The world of HR, as well as people in general, can be extremely random. Statistics help to understand, capture, and predict the randomness of our world. It can reduce risk by estimating uncertainties and reveal hidden aspects in day-to-day HR processes. For example, using analytics you can predict who is most likely to leave the organization, estimate whether you are rewarding different employees fairly, and discover biases in your hiring process. Without it, you miss out on a lot of valuable information needed to make better people decisions.
It’s always statistics in one form or another to the rescue!

Question 3: This sounds like statistical analysis is the solutions to all HR problems!
We wish it were. Unfortunately, statistical modeling can only explain part of the problem. We don’t live in a perfect world. Unlike theoretical math, which deals with direct computations, statistics are about probabilities.
Statistical models are always subject to unidentifiable factors called noise and inherent errors. Noise and errors make our predictions less certain. Having said that, a good statistical model will be invaluable and help to make much better people decisions.
Uncertainties are not bad. They are part of everything we do. The application of statistics reduces uncertainty to their lowest denominator. This provides HR with a robust and accurate decision support system.
Question 4: Apart from noise and errors, are there are any other drawbacks in the application of HR statistics?

Yes, bias! Bias can be a significant factor in any statistical analysis. This could be due to poor sampling, selective information or even lack of adequate data altogether.
Take the popular example of the school kid who took the third position in a race. Great job, kid! However, the race only had 3 participants. Perhaps a less than stellar performance after all. This is an example of selective information and could be solved by collecting more information.
In the real world, sampling biases could inject a substantial amount of selective information. It can even be deliberately designed to favor vested parties of interest, rather than representing the facts. This is not very different from accountants who cook up the financial records, isn’t it?
Question 5: So far, so good. Now, can you demystify the technicalities of statistics with real-world analogies, without the use of algebra?
Alright, game on!
Statistics has just three core parts, that’s all. These three musketeers (individually or combined!) can tackle any data-driven solution for HR under the sun!
The three parts are:
- Descriptive statistics
- Inferential statistics
- Statistical modeling
Question 6: Do we need to learn all three separately?
Nope, they are joined at the hip! Let me clarify all three through a real-world analogy:
Imagine both of us enter a sports auditorium and find a basket containing 4 sports balls in the middle. In this example, there are two tennis balls, one volleyball, and one soccer ball. We could refer to this as our dataset.

Now both of us, individually, are tasked to group the balls by their circumference. We don’t observe each other’s groupings, of course.


I identify 2 groups based on circumference:
I put them back in the basket. You repeat my exercise and identify 3 groups based on circumference.
Both of us have inadvertently used descriptive statistics when we grouped the ball by circumference. We then compared the groups to the total number of balls and gave our unique solutions. However, the important question is: Why did we group them differently?
Now, this is the essence of inferential statistics.
Question 7: Okay, did one of us group them incorrectly?
Nope, that’s the beauty of inferential statistics. Both of us are correct, only our inferences were slightly different. The soccer ball was 98% of the circumference of the volleyball.
For me, this 2% difference in size seemed insignificant. Therefore, I allocated them to the same group. To you, the 2% difference in size did seem significant, which made you allocate the two balls to two different groups.
See how we used the terms ‘significance’ and ‘inferences’ in conversational English? These terms for the backbone of any statistical analysis.
Question 8: So, the difference is significant to me but not to you. Significance is a matter of individual whim, is it?
Aha, that is only partly true! The decision can change even with the same level of significance. How? Let’s dig a little deeper and see where the idea of confidence level originates from.
Say, instead of just one soccer and volleyball, we had 10 balls of each type. We would then need to take the average circumference of 10 units (of both types of balls). Now the average of 10 soccer balls comes out to be 99% the circumference of the average of 10 volleyballs. An upgrade from 98%, isn’t it?
Here the 1% difference in size is insignificant to both of us. We, therefore, allocate both balls to the same group. See how our decision changed with a larger sample size? It’s important to note we are also more confident about our inference with a larger sample size. This confidence level is an important term often used in statistics.

Statistically significant outliers
Finally, let’s average 100 units of each type of ball. Now the soccer ball is 100% the average circumference of the volleyball. Now, even the most skeptic among us won’t have any doubts that the soccer ball set and the volleyball set are of the same circumference.
This explains statistics in a nutshell. It’s all about inferences levels (which can be tailored) and how we are more confident about our inferences the larger the sample size.
Question 9: If it’s that simple, why do we need metrics to compute p-values, levels of significance, confidence intervals, ANOVA’s, and so on?
There are two fundamental reasons why statistical calculations are much more complex
- There is much more variation between individual units in most real-life processes – including HR – compared to our previous example.
- We are measuring the difference between two groups of balls – and not between individual balls. Related to HR: we are measuring the difference between two teams of recruiters (and not between individual recruiters).
In our previous example, soccer balls and other types of balls undergo rigorous quality control in their manufacturing. This results in them having minimal variation. People, however, do not undergo “rigorous quality control” in their “manufacturing”. People are a lot more diverse and have a lot more variance between each individual unit.
Both examples, however, approximate a normal distribution in real-life.
Question 10: Okay, I have heard of this before, but what exactly is normality?
Let’s take the analogy of the soccer ball to another dimension using its shape. The distribution of real-life processes (like productivity per employee, or travel distance per day) when plotted on a chart manifest themselves in different shapes. However, because scores tend to stick to the average, they always follow the same pattern. They are more shaped like a rugby ball.
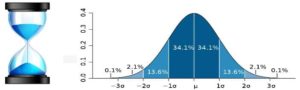
For the simplest explanation possible let’s take look at a sand hourglass.
The fine grains falling through the glass have a mini microns’ difference in size and weight. The pyramid, however, always follows an approximate normal distribution, time and time again (pun intended). Similar to a half rugby ball. This means variance patterns between different units are naturally expected to be within a certain range.
For another explanation of the normal distribution, look at this brilliant YouTube clip. Click the video to start – even though it looks grayed out, it works!
That’s exactly what most real-life data looks like. However, some processes are more like an hourglass on a stormy sea ride. Take for example performance ratings. These are skewed to one side because managers don’t like to give people low ratings. These don’t form a normal distribution. It’s hard to differentiate people when they all score the same, that’s why one of the core issues in statistics is testing for normality. The picture below shows the skewed performance distribution and the mean (average), median (value in the middle), and mode (most common value in the data set).
Every time we analyze data, we need to check if our HR data follow this hourglass-like distribution on a calm sea.
Question 11: So, does that simply mean that in a normal distribution variance must be within acceptable limits?
Exactly. A perfect normal distribution translates to 66.6% of the dataset lying within 2 standard deviations from the mean and 99.7% within 3 standard deviations. Standard deviation is a measure of dispersion, similar to measuring the variance of the width of a rugby ball from its center.
If our HR data closely follows the shape of a normal distribution, we can be sure that any statistical inference will have a good measure of accuracy.
Question 12: So, what if our rugby ball – sorry, HR data – isn’t normal? Is that the end of reliable statistical analysis?
Nope, absence of normality is not abnormality. There is a working compromise here; we could use the median instead of the mean. The median is an estimation of centrality similar to the mean. We could use non-parametric methods to execute our statistical analysis but the results are touted to be less robust in real-life scenarios.
However, as a statistician, I feel non-parametric methods are one of the simplest and underutilized aspects of statistics.
Anyway, there are other hacks that you can use in your statistical analysis. Like box-cox transformations, removing outliers (to force normality), and others. However, this is slightly beyond the scope in this post. Please do bear in mind that there is always a hack to any statistical analysis!
Question 13: I think I have a broad overview of the capabilities and limitations of statistics: The normal distribution, variance, and statistical inference. Can you give me a real-life HR example of a normal distribution and its statistical analysis?

Sure thing! Let’s take two identical pictures of our rugby ball. Then, take two printouts of it and randomly put a hundred dots on both the pictures (roughly covering the entire surface of the image). The images of the rugby balls are identical, but the pattern of dots on both the balls aren’t identical.
Why? Many of the random 100 dots on both the rugby balls have varying distances from the center of the image (mean). Therefore, it’s hard to tell the overall difference without measuring the distances of all the dots.
Now, replace the 2 rugby ball images with 2 recruitment teams of a global recruitment center in HR. Each image, or global recruitment center, has 100 recruiters. Replace the random dots with the recruitment performance of each recruiter.
The exact center of the rugby ball represents the mean performance of each team. Are the performances of both teams equal? It’s the same case. The same rugby ball. The same 100 recruiters. The same overall area. However, because the dots are scattered differently over the rugby balls, the overall performances aren’t necessarily the same.
Question 14: So the performances of both the teams aren’t certain to be equal. This means that the performance of individual recruits becomes key.
Yup, spot on! Instead of just one factor (the mean), we now have two factors (the mean AND the variance) that are important.
Comparison between the mean and the variance is the soul of statistics.
The mean (average of all recruiters’ performances) and variance (the distance of each recruiter from the mean). Master these two concepts and you’ve mastered 90% of applied statistics. I mean it (pun intended)!
All hypothesis tests in statistics, including T-Tests, ANOVA, Chi-Square and more, depending upon equations derived from:
- Mean or median (average of all recruiters’ performances).
- Variance (the distance of each recruiter from the mean).
- The total number of population (The sample of recruiters, i.e. n).
And in some cases
- Values from z-distribution tables (pre-computed normal distribution tables).
That’s all there is to it! As you can see, this breaks all statistics down to their 4 lowest denominators.
Question 15: Awesome! Do we typically need to do all these tests on HR data?
The exact tests would depend upon the type of insights required for the business. A typical starting point would be a t-test or an ANOVA. ANOVA literally stands for analysis of variance. Both of these check whether there is a significant overall difference between the mean of two groups, such as two HR recruitment teams.
Question 16: Can we do a t-test on our recruiter performance data?
Sure. We select a sample set from our data. Say the performance of 30 recruiters (out of 100) from each team. These are randomly selected, of course, to eliminate any bias.
Now we have the data in terms of average performance (of both the sample and the total) and the variance. That’s all the data we will need.
We apply the t-test formula. It’s a linear algebra jugglery on the mean, the variance and the total number of recruiters. We will explain the logic behind the formula in a next article:

The computation will take about 12 minutes via hand calculations (using a basic calculator) or a few seconds using a statistical analysis software or an Excel macro.
Now the output could be something like: t = -3.73, p = .07.
The t-value is the outcome of the t-test. P stands for probability. In this case there’s a .07 (7%) probability that our findings are random – and a 93% probability that these are actually true (not caused by randomness or chance).
Based on the same report, we could still end up with different answers to our hypothesis. Why?
Because our understanding of the “significance of difference” for the p-value of t-test was different. In other words, your criteria for significance of the p-value was smaller than .10, whereas my criteria for significance was smaller than .05.
The p-value in our test is .07.
Let’s compare the p-value of the test to our individual level of significance:
- .07 > .05 (my value of significance)
- .07 < .10 (your value of significance)
In your case, the p-value of the test was lower than your value of significance. This means that, according to you, there was a significant difference in the mean between the two groups.
In my case, the p-value of the test was higher than my own value of significance. Therefore, I don’t think that there is a significant difference between the two groups.
The p-value means the chance that the difference between the two groups comes from random chance. As in, there is no actual difference between the two groups. In our case, there is a 7% chance that the difference between the two groups is due to chance. This was enough for you to conclude that there was a significant difference between the two groups. I had higher standards and thus did not think that this chance was low enough to warrant the same conclusion.
Question 17: What would happen if we were to increase the sample size?
Interestingly, if we change the sample size from 30 to 100, the value of p increases to .15. This would mean that there was no difference in performance between the two teams according to both of our inferences.
- .15 > .05 (my value of significance)
- .15 > .10 (your value of significance)
As you can see the inferences (decisions) change with changes in sample size.
Question 18: What about other aspects, like confidence intervals?
The narrower the confidence interval, the more confident we are about our analysis. If our data-set follows normality than its width should inversely correlate with sample size. This follows the central limit theorem. I will cover this and other key aspects of statistical tests in the next part. This part was just to give an overview of the discipline of applied statistics and its relevance to HR.

Question 19: Where can I learn more about statistics in HR?
That’s a good question! We created a course specifically on Statistics in HR. In this course, we will cover multiple topics, split into four modules.
- Introduction to statistics
- Methodology
- Basic statistical tests
- Advanced statistical tests
In module 1, you will learn how statics affect your everyday life and how it can help us in HR. You will learn about simple techniques to understand data better, like the mean, mode, median, and range. You will learn about the spread of data, how this influences your data analysis, and finally, you will learn techniques to clean and visualize data. The first two modules prepare you for the actual analytics in module 3 and 4.
In module 2, you will learn more about methodology. Statistics and methodology go hand in hand. One cannot work without the other. In this module, you will learn about sampling, bias, probability, hypothesis testing, and conceptual models. These are key concepts to understand before you can accurately analyze your data.
In module 3 and 4, you will learn basic and advanced statistical tests. We will start with correlation analysis, t-test, and ANOVA. In the second part, you will learn about linear regression, multiple regression, logistic regression, and structural equation modeling.
We dedicate a full lesson to explaining each of these tests. We will explain how these tests work, when they can be applied, the core assumptions of these test, and we will link you to various resources to execute these tests in the software that you use.
Because these tests can be done using Excel, SPSS, R, or another statistical package, we focus the lessons on a step-by-step process of doing the test which is independent of the software you use. This means that you will have all the information to do this test regardless of whether you’re using R or SPSS.
Ready to Bring HR Analytics to The Next Level?
The Statistics in HR course teaches you essential statistical skills including key concepts like probability and significance. When you apply these skills to solve the right problems, you will be able to create unique results and play a pivotal role in translating HR data into value-adding insights.
Even if you don’t have any experience crunching numbers and running statistical tests, this course will get you up to speed in no time. Upon completion, you will be able to quickly test practical hypotheses, know when to apply a certain type of statistical test, and how to interpret its outcomes.















